
Designing Data-Intensive Applications. Chapter 6
In this chapter, the author explores the different types of partitioning, also known as sharding, and the different approaches for rebalancing partitions.
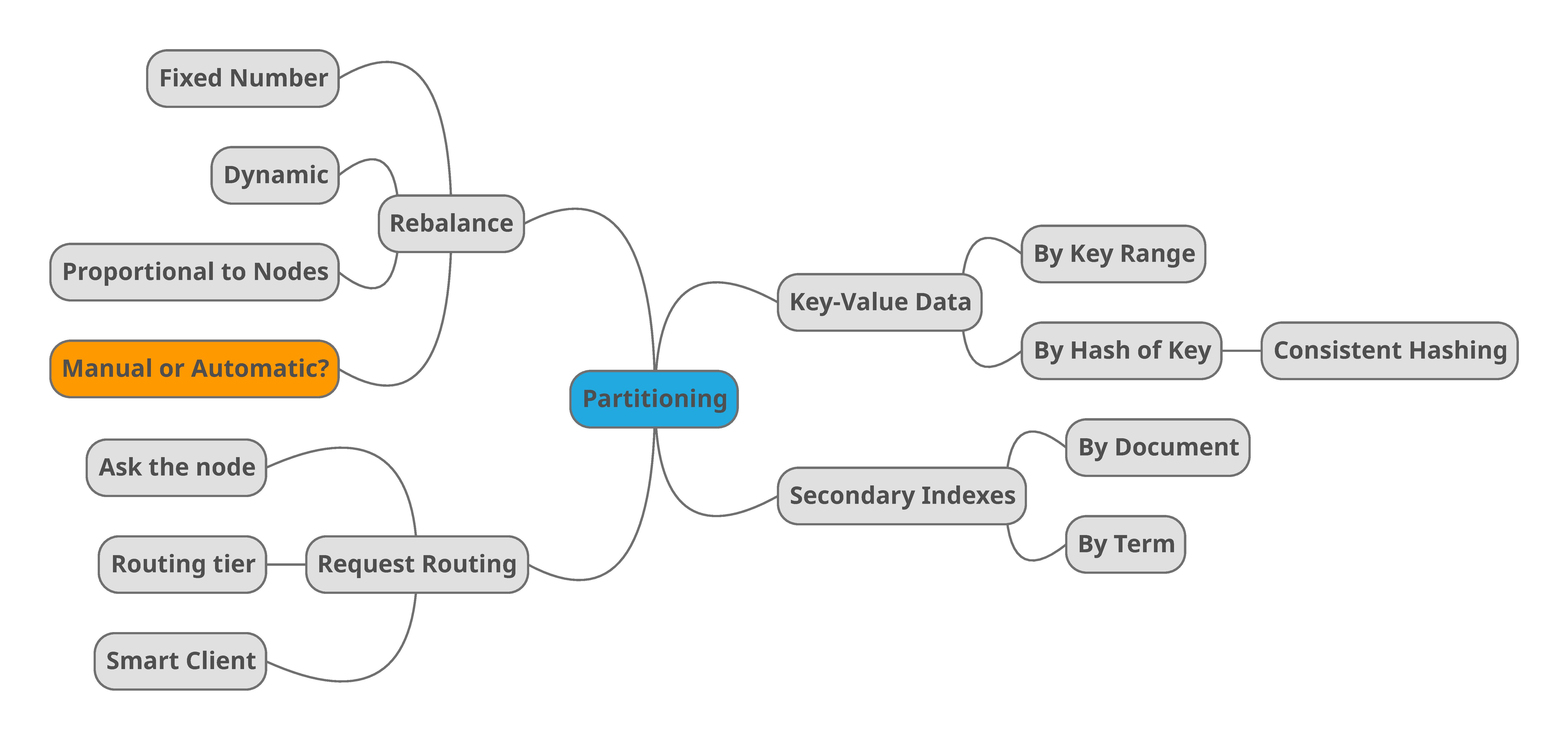
Partitioning
The main reason for partitioning the data is scalability. The partitions can be stored on different nodes as a shared nothing cluster. Thus, a large data set can be distributed across many disks.
The goal is to spread the data and the query load across nodes.
Partitioning by key
Partitioning by Key Range
One way of partitioning the data is to assign a continuous range of keys to each partition. Knowing the boundaries between the ranges, it is possible to determine which partition contains a certain key. If you also know which partition is assigned to every node the request can be done directly to the specific node.
This approach can lead to hot spots for certain accessing patterns where partitions are not well balanced.
Partitioning by Hash of Key
To solve the problem of hot spots many distributed data stores use a hash function to determine the partition for a given key.
This technique is a good choice to distribute keys accordingly among the partitions.
Partitioning secondary indexes
The partitioning schemes above are based on key-value data. The situation is different if what we use is a secondary index to access the data. Secondary indexes don’t map directly to partition because they usually don’t identify a record uniquely.
Partitioning Secondary Indexes by Document
In this approach, each partition will keep its own secondary indexes. For instance, if you search by all red cars you need to send the query to all nodes and combine the results back. This option can make read queries on secondary indexes quite expensive.
Partitioning Secondary Indexes by Term
Instead of having each secondary index in each partition, this option creates a global partitioned index covering data in all partitions. The term searched is included in the global index.
The reads are more efficient than by Document. By the contrary, the writes are slower and more complicated.
Rebalancing partitions
Rebalancing has to meet at least these requirements:
- The database should accept request during rebalancing.
- No more than the necessary data should be moved to make the process faster.
- The data should be stored fairly after the rebalancing.
Strategies when rebalancing:
- Fixed number of partitions.
- Dynamic.
- Proportional to nodes.
 provided by @mintxelas
provided by @mintxelas