
Designing Data-Intensive Applications. Chapter 2
Data Models and Query Languages
Relational databases
Most applications store the data using relational tables. In order to access that data, it requires a translation between the application objects and the database model. That is called impedance mismatch. ORM frameworks can help to deal with the amount of boilerplate code needed for this translation but they cannot hide entirely the differences between the two models.
Some time ago, I wrote a post about that topic. impedance mismatch.
Data duplication and document databases
In terms of data, no duplication requires many-to-one relationships. The advantage of it is the data will not be duplicated across other entities in the database. Unfortunately, that model does not fit particularly well into document databases.
Usually, the support for joins in document databases is not as good as relational systems. Joins can be replaced by application code but this may lead to additional complexity in the application.
Which data model leads to a simpler application code?
One of the main differences and advantages between relational and document model is in situations where an application wants to change the format of the data. Most document databases do not enforce any schema in documents which may be a good option for certain scenarios. Also, if the application’s data looks like a document structure where the whole tree requires to be loaded then a document based approach might be a good idea.
On the other hand, if your application uses many-to-many or many-to-one relationships the document database might not be the best option.
Most of the relational databases support saving JSON or XML objects. This allows the application to use the relational and the document model with the same database system.
Graph-Like Data Models
If many-to-many relationships are very common in your data, a graph data model might be more natural than a relational model. They target use cases where anything is potentially related to everything.
A graph contains two types of objects: vertices (nodes or entities) and edges (relationships or arcs).
As the post before, I will share the mind map Fermín made for this second chapter.
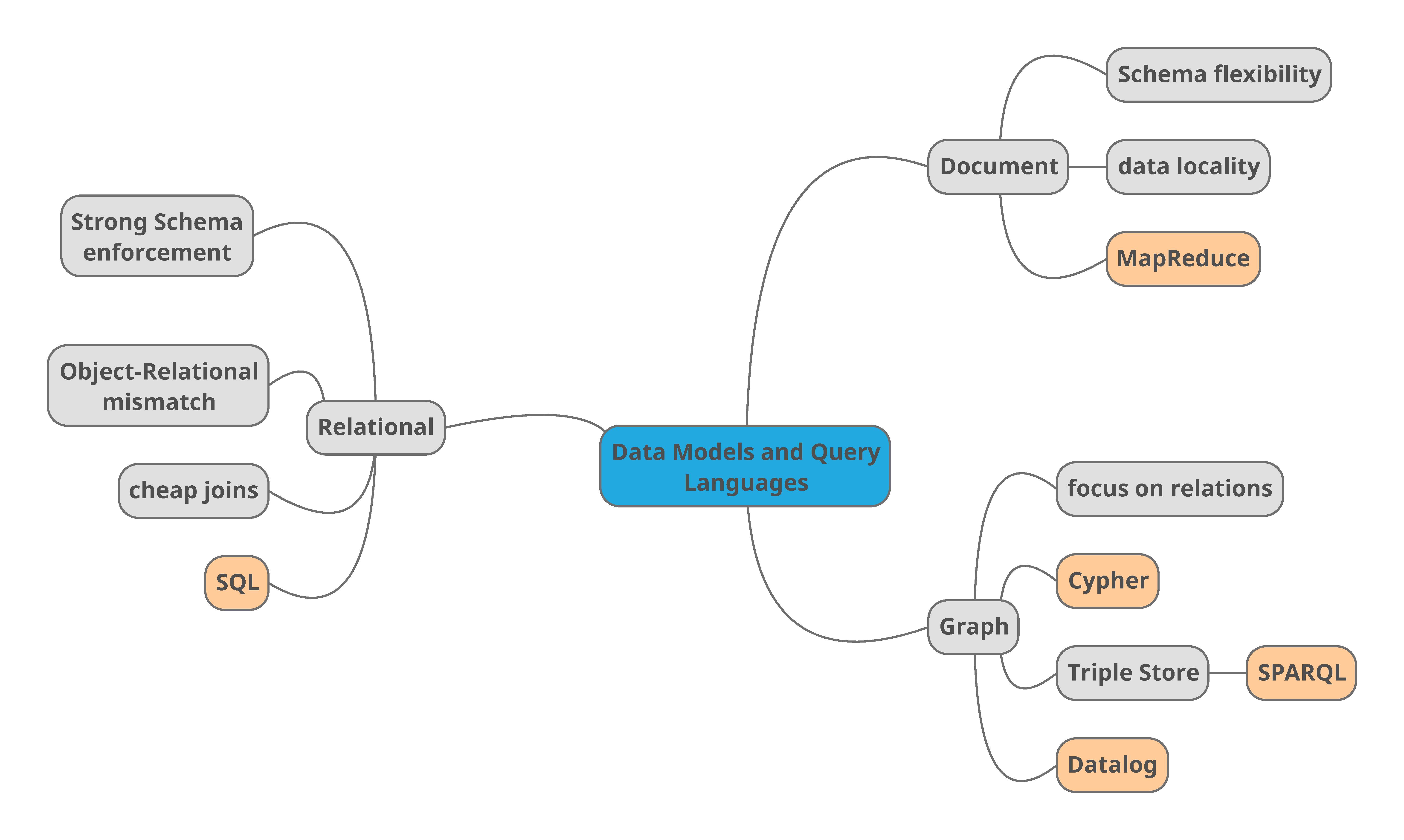
<- Chapter 1. Reliable, scalable and maintainable Applications